积积积桶积积的桶直接看积积积桶积积的桶直接看爆火的DeepSeek-V3强在哪?_ZAKER新闻
积积积桶积积的桶直接看爆火的DeepSeek-V3强在哪?_ZAKER新闻
对于此次打折兑付,上述播州国投工作人员表示,其对该方案并不是很清楚,可能只是长安资产针对急用钱的客户提供的一种方案选择。长安资产客服工作人员也强调,目前方案并非播州区整体方案,而是市场上一笔资金(提出的方案),只能接一小部分份额。该项目仍在正常催收当中,如果后续有(政府)化债政策还是会统一走化债政策。
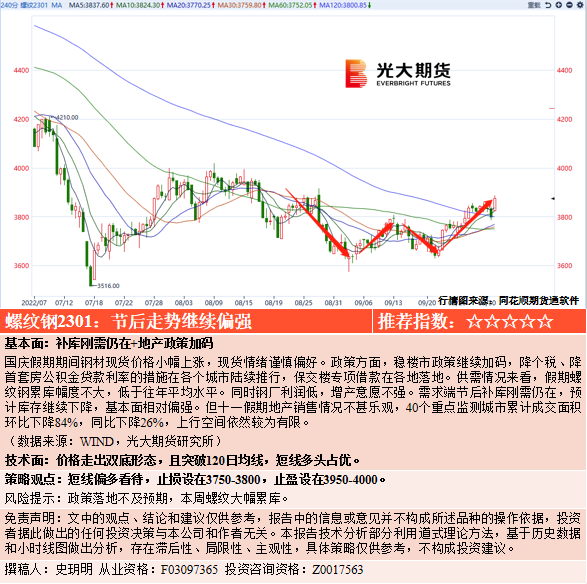
最近,DeepSeek-V3 在国外火了。它为什么火呢?主要有三个原因:一,性能非常出色。在许多测试中,它都超过了其他顶尖模型,比如 GPT-4o 和 Claude 3.5 Sonnet。特别在数学和代码生成方面,表现尤为突出。二,它的训练成本相对较低。只要 600 万美元就能完成训练,与其他顶级模型相比,性价比极高。三,它是开源的。全球的开发者都可以免费使用和测试它。因此,它火了。不过,随着它的火爆,很多人开始好奇:这个模型来自哪里?它与其他模型有何不同?带着同样的疑问,我查看了它 12 月 26 日在 GitHub 上发布的报告—— DeepSeek-V3 Technical Report。总结出五点内容,关于模型架构设计、基础设施、预训练、后训练模型,以及评估结果。现在向你汇报一下。一先来说说这家公司:DeepSeek-V3 由中国幻方量化公司开发,它是基于自研 MoE 模型的新一代大语言模型。MoE,全称 Mixture of Experts,也叫混合专家技术,是一种机器学习架构,是通过组合多个专家模型,在处理复杂任务时,让效率和准确度都大大提升。以前,人们总爱把 "DeepSeek" 比作 AI 界的拼多多。因为它开启了中国大模型的价格战。2024 年 5 月,它们推出了一个名为 DeepSeek V2 的开源模型。这个模型的性价比超级高,每百万个 token 的推理计算成本只要 1 块钱。这个价格,大概是 Llama3 70B 的 1/7,也是 GPT-4 Turbo 的 1/70。这个消息一出,字节、腾讯、百度、阿里,还有 kimi 这些 AI 公司都跟着降价。所以,DeepSeek 凭借它的高性价比,在中国大模型市场掀起了第一场价格战。但是,V2.5 版本的更新速度不快,直到 9 月份才有动静;现在又过了 3 个月,V3 版本终于来了。这次,大家最想知道的就是,它的架构有什么新变化。这家公司的老板梁文锋说过,以前中国公司习惯于做应用变现,但现在 DeepSeek 的目标是走在技术前沿。他希望用技术推动整个生态的发展。他认为,中国公司应该从 " 搭便车 " 的角色,转变为 " 贡献者 ",主动参与到全球创新的大潮中。那么,DeepSeek-V3 到底有哪些技术架构上新亮点呢?图释:DeepSeek-V3MoE 架构工作流程 报告中说:DeepSeek-V3 的架构设计非常精巧,主要有四点:分别是什么意思呢?首先,DeepSeek-V3 有 671 亿个参数,像一个超级大脑。这个大脑采用的技术叫做 MoE 架构,就是混合专家技术。这意味着它里面有很多专家模型,但每次只需要调用 37 亿个参数来工作就可以了。为了让专家模型高效工作,DeepSeek-V3 得有个聪明的调度员,确保每个专家都有活干,不会有的很忙,有的很闲。因此,DeepSeek-V3 装载了信息过滤器,叫做 "MLA",它能让模型只关注信息中的重要部分,不会被不重要的细节分散注意力。但是,这样还不够,DeepSeek-V3 还得确保每个专家都能得到合理的工作量,并且训练模型去预测接下来的几个步骤,不只是下一步;这就是无辅助损失的负载平衡策略和多令牌预测训练目标的用处。简单来说,让每个专家都有合理的工作量,同时训练模型去预测接下来的几个步骤,这样模型在实际工作中就能表现得更好,比如在处理长篇文章时能更好地理解上下文。所以,DeepSeek-V3 的架构有四个要点:一,MLA 技术,通过压缩注意力机制减少需要处理的信息量,提高效率。二,DeepSeekMoE 技术,用更细粒度的专家和共享专家提高训练效率,并且动态调整专家间的工作量均衡。三,无辅助损失的负载平衡策略,确保专家间工作量均衡,不依赖额外的损失项;四,多令牌预测训练目标,提高模型的预测能力和数据效率。总之,DeepSeek-V3 的架构,像一个高效的团队,每个成员都有特定的任务,而且团队能够预测并准备接下来的工作,这样的设计才能让模型在处理信息时既快速又准确。二报告第 11 页到第 12 页详细讲解了 DeepSeek-V3 的训练技术。首先,DeepSeek-V3 是在拥有 2048 个 NVIDIA H800 GPU 的超级计算机上进行训练的。这些 GPU 通过 NVLink 和 NVSwitch 在单个节点内连接,节点之间则通过 InfiniBand 连接,形成了一个强大的分布式计算网络。接下来说说训练框架。DeepSeek-V3 用了一个叫做 DualPipe 的算法,这个算法能让模型更智能地分配任务,减少等待时间,确保每个部分都能在正确的时间做正确的事。这个算法具体包括两点:一,DualPipe 和计算通信重叠。就像两组工人,一组加工零件,一组准备材料。如果他们不同步,加工好的零件就会堆积。DeepSeek-V3 的 DualPipe 算法让这两组工人的工作节奏同步,一边加工零件,一边准备材料,这样就没有等待时间,生产过程更流畅。二,高效实现跨节点全对全通信。你可以想象一个大工厂的不同车间需要共享信息。DeepSeek-V3 通过高效的通信技术,确保不同 " 车间 " 之间的信息能快速共享,就像建立了一个快速的信息传递网络。两者组合,就能在有限的硬件资源下训练更大的模型。有了算法还不够,还要精练。怎么精练?DeepSeek-V3 推出了一种叫 FP8 的新技术。简单来说,通过五个步骤用更小的数字代替原来的大数字,让计算机更快地做计算,同时节省电力。举个例子:在超市买东西,大多数情况下不用精确到小数点后,大概齐就行了。但是,用小数字代替大数字可能会影响精细工作。怎么办?DeepSeek-V3 在关键的地方会用更精确的大数字来确保质量,比如:矩阵乘法,这就像在做精细活儿时,在关键步骤用上好工具,其他时候用差点的也没事。在训练过程中,DeepSeek-V3 还会用 FP8 存储中间结果,节省更多的内存空间。这就像整理东西时,不用把所有东西都放在显眼的地方,而是合理地收纳起来,需要时再拿出来。最后,DeepSeek-V3 在实际使用时也会根据情况来决定用不用 FP8,这样就能在保证效果的同时,让模型跑得更快,更省资源。如同我们在日常生活中会根据不同的情况来选择不同的工具,既高效又节约,这就是它的底层基础技术。三DeepSeek-V3 是怎么做预训练的呢?报告里说,DeepSeek-V3 的预训练涉及六个方面:数据建设、超参数调整、长上下文扩展、评估基准、消融研究,还有辅助无损耗平衡策略。首先是 " 数据建设 "。DeepSeek-V3 用了 14.8 万亿个高质量的数据点来训练,这些数据覆盖了很多不同的领域和语言,这样模型就能学到很多不同的知识。然后,在训练开始之前,得设置一些重要的参数,比如学习率。DeepSeek-V3 会仔细挑选这些参数,让模型能以最好的方式学习,这叫超参数调整。紧接着,对长上下文扩展。这就像教模型读长故事。DeepSeek-V3 用了一些特别的技术,比如 YaRN,来增加模型能处理的文本长度,从 4K 字节增加到 128K 字节。这样,模型就能理解更长的文章和故事了。在学习的过程中,还得检查模型学得怎么样。这就是 " 评估基准 " 的作用。DeepSeek-V3 会在各种测试上进行评估,比如 MMLMU-Pro、GPQA-Diamond 等,确保模型在不同的任务上都能表现得很好。图释:DeepSeek-V3 训练数据的方法 消融研究是什么?DeepSeek-V3 会做很多实验,看看哪些方法最管用。比如研究无辅助损失的负载平衡策略,找出哪些技术最能提高模型的性能等。最后,模型通过动态调整,使得每个专家的工作量更加均衡,而不是通过辅助损失来强制平衡。如此一来,预训练阶段就能吸收和处理很多信息,学会理解和生成文本,为后面的训练打下坚实的基础。看完这段报告后我觉得,训练模型就像给一个 5 岁孩子提供学习资源和环境一样,让它在成长过程中能够全面发展。四问题是:只有预训练还不够,后训练才能让模型更成熟。那么,DeepSeek-V3 是怎么做的后训练呢?首先是监督微调。DeepSeek 团队为模型准备了 150 万个实例的特别训练集,就像是一本包含各种生活场景的百科全书。每个训练集都是精心设计,确保模型能学会在不同情况下应该怎么处理。对于那些需要逻辑和计算的数据,比如数学问题或者编程挑战,团队用了一个已经训练好的模型来生成例子。虽然这些例子通常很准确,但有时可能太复杂或者格式不规范。所以,团队的目标是让数据既准确又容易理解。为了做到这一点,他们结合了监督微调和强化学习的方法,训练了一些 " 专家模型 "。这些专家模型就像专业的老师,负责教模型如何在特定领域做得更好。在训练过程中,他们会创造两种类型的例子:一种是直接的问题和答案,另一种加上了 " 系统提示 " 的问题、答案和 R1 模型的响应。这些系统提示就像教学大纲,指导模型如何给出有深度和经过验证的答案。对了,在 " 强化学习 " 阶段,模型会尝试不同的回答,根据效果得到奖励或惩罚。通过这个过程,模型就学会了给出更好的答案;最后,团队会用 " 拒绝采样 " 的方法挑选最好的示例,用于最终模型的训练,这确保了用于模型学习的数据既准确又容易理解。对于非推理数据,比如:写故事或者角色扮演,团队用了另一个模型来生成回答,然后让人工检查这些回答是否准确和合适。这两个步骤,报告中称之为 " 评价标准 "。最后,DeepSeek 团队对 DeepSeek-V3-Base 进行了两个时期的微调,采用了从 5×10-6 到 1×10-6 的 " 余弦衰减学习率调度 "。在训练期间,每个序列都由多个样本组成,但他们采用了 " 样本屏蔽策略 ",确保示例相互独立,这是一种 " 开放评估 " 的模型。通过这些后训练步骤,DeepSeek-V3 能够在实际应用中做到更加精准,就像完成基础训练后,再给它进行一些专业技能的培训。他们给它起的名字叫 " 生成奖励模型 ",这让它不仅是一个学习者,还成为了一个评委;如此周而复始,建立一套正向反馈机制。五那么,通过这套模型训练出来的成果如何呢?DeepSeek-V3 做了一系列的全面基准测试,这些测试相当于给超级大脑出了一套标准化的试卷,看看它在各个科目上能得多少分。这些科目包括教育知识、语言理解、编程技能、数学问题解决等。在数学推理上:在 MATH-500 测试中,DeepSeek-V3 得了 90.2 分,这个分数不仅比所有开源竞争对手高,比如 Qwen 2.5 的 80 分和 Llama 3.1 的 73.8 分,也超过了闭源模型 GPT-4o 的 74.6 分。在 MGSM 测试中,DeepSeek-V3 得了 79.8 分,超过了 Llama 3.1 的 69.9 分和 Qwen 2.5 的 76.2 分。在 CMath 测试中,DeepSeek-V3 得了 90.7 分,比 Llama 3.1 的 77.3 分和 GPT-4o 的 84.5 分都要好。图解:DeepSeek-V3 基准测试数据 在编程和编码能力方面:在 LiveCodeBench 测试中,DeepSeek-V3 的通过率达到了 37.6%,领先于 Llama 3.1 的 30.1% 和 Claude 3.5 Sonnet 的 32.8%。在 HumanEval-Mul 测试中,DeepSeek-V3 得了 82.6%,比 Qwen 2.5 的 77.3% 高,并且和 GPT-4o 的 80.5% 差不多。在 CRUXEval-I 测试中,DeepSeek-V3 得了 67.3%,明显优于 Qwen 2.5 的 59.1% 和 Llama 3.1 的 58.5%。在多语言和非英语任务上:在 CMMLU 测试中,DeepSeek-V3 得了 88.8 分,超过了 Qwen 2.5 的 89.5 分,并且领先于 Llama 3.1 的 73.7 分。在 C-Eval,中国评估基准测试中,DeepSeek-V3 得了 90.1 分,远远领先于 Llama 3.1 的 72.5 分。其他数据还有很多,总的来说,DeepSeek-V3 成绩遥遥领先;对了,还有一句要提的是:DeepSeek-V3 的训练成本只有 557.6 万美元,这只是训练 Meta 的 Llama 3.1 所需估计的 5 亿美元的一小部分。所以,DeepSeek-V3 新的模型结构,无疑是如今人工智能领域中一次新的变革。高效、省力、省成本;难怪连 OpenAI 的前首席科学家 Andrej Karpathy 也表示,这是一次 " 令人印象深刻的展示 "。如果 DeepSeek-V3 在资源有限的情况下,都能表现出如此卓越的工程能力,以后是不是不需要大型 GPU 集群了?这个问题值得我们思考。koa12jJid0DL9adK+CJ1DK2K393LKASDad
编辑:吴家栋
TOP1热点:我国首个超深水气田
在今年2月份,也有市民询问312国道双照收费站拆除期限,中共咸阳市委督查室回复:按照2003年8月18日陕西省人民政府《关于国道312咸阳至永寿一级公路收费经营权转让的批复》(陕政函[2003〕152号),该收费站应于2023年8月31日到期。因2020年2月17日至5月5日(共79天)期间新冠肺炎疫情防控免收车辆通行费政策的执行,2021年4月,省交通运输厅、省发改委、省财政厅印发《关于顺延收费公路收费期限的通知》(陕交发〔2021〕33号)确定咸永公路收费期限从原来的2023年8月31日延长到2023年11月 18 日,到时将撤销收费站。。
TOP2热点:为什么煮饺子要经常给锅里浇水
财联社11月20日电,有消息称,监管机构正在起草一份中资房地产商白名单,可能有50家国有和民营房企会被列入其中,在列的企业将获得包括信货、债权和股权融资等多方面的支持,这一名单较今年年初具有系统重要性优质房企的范围有所扩大。一家国有大行相关人士表示,听说了拟定房企白名单一事,“目前还在等着人民银行下名单,但有的银行已经开始向重点客户展开营销了。”(财新)
TOP3热点:不良人第七季定档二次元人物桶二次元人物免费观看
因为一名曾经在加拿大驻华大使馆工作过的前外交官就直言不讳地对《环球邮报》透露,尽管加拿大驻华大使馆那个从事情报工作的部门并不属于加拿大安全情报局这个加拿大的正牌间谍机构,但这个部门搜集的情报对后者而言一直是“很有价值”的。所以——这名前外交官说——也难怪中国方面会将康明凯视作间谍。
中新经纬梳理发现,国内成品油在今年已历经二十二轮调整,呈现“十涨九跌三搁浅”的格局,汽油价格累计上涨760元/吨,柴油价格累计上涨730元/吨。
TOP4热点:写作新人计划西施狂飙乳液
文章同时指出,海关系统反腐败形势依然严峻复杂,仍需警惕各类腐败风险。海关执法领域仍有顽瘴痼疾、非执法领域问题客观存在等现象也不容忽视。
TOP5热点:冲锋衣平价推荐总裁受夹震蛋H调教s m视频
2023年7月,山西尧都农商行召开年度股东大会,审议关于吸收合并旗下尧都惠都村镇银行、太原信都村镇银行等相关议案,但目前未披露进展。
TOP6热点:蛇拿九稳答题挑战Brandilovemissionaryaction
蒋圣龙说,东亚杯那场比赛,自己对韩国队中锋曹圭成有很深印象,后者也代表韩国国家队在世界杯上有过两个进球,“我们看了世界杯的比赛,知道他在世界杯进了两个头球。”
台湾《联合报》称,中国国民党不分区民代名单还包括智库执行长柯志恩、台南市前议员谢龙介。报道称,由中国国民党中评委推荐的名单中,并没有韩国瑜的名字,但作为党主席,朱立伦有“最终推荐权”。
TOP7热点:AI 推文赚钱pansy中老年妈妈
扬科维奇说:“我们作为一个球队要对比赛保持专注,比赛过程要保持球队内部的沟通,在泰国的比赛中我们也面对了球迷坐满的场面,但我们克服了困难,利用队内沟通,控制比赛节奏并获得了胜利。明天我们有最好的球迷的支持,我们仍要保持专注度,要专注自己。有这么多球迷,对球队肯定是巨大的支持和鼓励。”
TOP8热点:电压锅和高压锅哪个好暴躁妹妹csgo
“但凡是变动,总是伴有机会。”丘成桐补充道,“很多受到美国歧视和压迫的顶尖人才,比如俄罗斯和伊朗裔学者,都表达了希望来中国的意愿。同时,最近这几年,很多中国留学生也开始陆续地回来。”
TOP9热点:知乎推文加入小杰快拨出我是你小䧅视频
财联社11月20日电,11月1年期贷款市场报价利率(LPR)报3.45%,上月为3.45%;5年期以上LPR报4.2%,上月为4.2%。
TOP10热点:美国一架客机坠河积积积桶积积的桶直接看
“今年以来,广州土拍市场冷热分化明显,冷门地块乏人问津,热门地块则纷纷触顶摇号,改为‘价高者得’之后,意味着今后房企在广州想要拿到好地块,将从原来的‘实力+运气’改为完全‘凭实力’,热门地块的竞争将会更加激烈,也更考验房企的算账水平。”肖文晓续称。
此次在浙江调研期间,訚柏强调,<span>要依法加大对民营企业工作人员腐败行为的惩处力度,推动民营企业合规守法经营,建设法治民营企业、清廉民营企业。</span>